Anlamsal Ağ’da veri sınıflandırmaları, bir web sitesi için her zaman manuel etiketlemeler ile mi devam edecek? Peki biz bu etiketlemeleri yapmazsak Google hiçbir şey anlamayacak mı? Aslında bu soruların cevabı çok basit: Eğer işin içinde yapay zekâ yoksa, her şeyi biz belirtmeliyiz. Yapay zekâ ve “deep learning” var ise sınıflandırmalar, anlamlandırmalar kendi kendini besleyeceğinden bir süre sonra ilgili yazılım, geliştiricilerin doğrudan işaretlemediği verileri de kendisi sınıflandırabilecektir. Güzel olan şu ki Google hâlihazırda kendi algoritmalarında sınıflandırma yaparken yapay zekâ kullanıyor. Yani tüm veri işaretlemelerinin de ötesinde veriler arasındaki ilişkileri Google kendisi sağlayabiliyor. Örnek olarak Moz’dan Alexis Sanders’ın yazısından aldığım iki grafiği inceleyebiliriz:
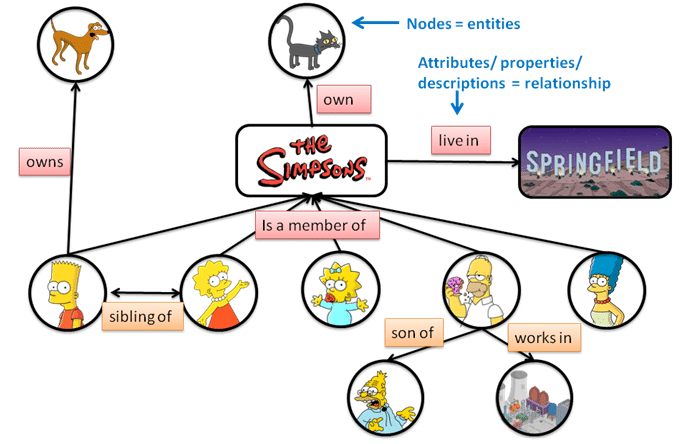

Google getirdiği Answer Card sonucunda Homer Simpson’ın çalıştığı yere dair verdiği cevabı vurgulu şekilde gösteriyor.
Arama motorlarının neden Semantik Web’e ihtiyacı var?
Dünyada her geçen yıl ciddi miktarda veri boyutu artışı yaşanıyor. Neredeyse her yıl katlanarak yükselen bu gezegen büyüklüğündeki veri havuzunda bilgi kirliliği de kaçınılmaz oluyor. Burada doğru ya da yanlış bilgiden söz etmiyorum. Botların anlaması gereken ve özgünlüğüne, kalitesine karar vermesi gereken, her gün yenileri eklenen bilgilerin miktarından söz ediyorum. Her gün webe binlerce websitesi katılıyor. Arama motorları için bu kadar veri bombardımanı içerisinde kullanıcıların isteklerine uygun verileri bulmak, hurdalıkta işe yarar bir şeyler bulmaya benzemeye başladı. Tüm operasyonlarını web üzerinde yeni veriler keşfedip, dizinlerine ekleyip, sınıflandırmaya harcayan arama motorlarının mümkün olduğunca verimli performans gösterebilmesi için; anlam ilişkilendirmelerini daha iyi sağlaması gerekmekte.
Yukarıdaki
grafik dünya çapında Big Data işleme üzerine bugüne dek pazar
gelişimini ve gelecek yıllarda pazarın ne kadar büyüyeceğine dair
tahminleri göstermektedir.
Semantik Arama İhtiyacını Doğuran 5 Motivasyon
1 – Kullanıcı talebini doğru şekilde anlama
Bu durumu bir örnekle açıklamak istiyorum. “Araba” ve “otomobil” kelimeleri aynı anlama gelmektedir. Google’a otomobil yazdığınızda ilk sayfada sadece otomobil satış siteleri çıkmaktadır. Ancak “araba” yazdığınızda ilk sayfadaki iki sonucun oyun sitelerine ait olduğunu göreceksiniz. Bunun nedeni “araba” kelimesinin otomobil kelimesine göre çocuklar tarafından yetişkinlere göre biraz daha fazla kullanılması, aramayı yapan çocuk kullanıcıların, satın almak yerine araba oyunları oynamak için bu aramayı yapmalarıdır.Ancak en önemli sebeplerden birini de araba kelimesinin geçtiği diğer Google aramalarına baktığımızda keşfediyoruz. “Araba oyunları” araması gibi sorguların araba ve oyun kelimeleri arasında ilişkilendirmeyi kuvvetlendirerek sonuçlara yansıyacak kadar çok yapılmasıdır. “Otomobil” aramasında ise aynı korelasyon görülmemektedir.

Yukarıdaki görsel Google “araba” araması sonuçlarından alınmıştır.


2 – Spame karşı yönetilebilir efor ve maliyetle mücadele
Spam çalışmaları ile manipülasyona uğramamak için arama motorları veriler arası korelasyonları daha iyi tespit etmek ve daha iyi yorumlamak zorunda. Örneğin bir anda çok fazla “backlink” almaya başlayan bir sitenin aramalarda benzer şekilde trend artışının olmaması doğal olmayan bir durumun işaretçisi olabilir. Yani bir site hakkında ne kadar çok konuşuluyorsa ona bağlantı veren site sayısının da aynı ölçüde artması beklenirken, bağlantı veren site sayısı ciddi şekilde artıyor ancak ilgili sitenin arama hacminde benzer bir artış görülmüyorsa bu durum pek iyi niyetli değerlendirilmeyecektir.3 – Kaliteli ve kalitesiz içerikleri bir insan gibi yorumlayıp, ayırt edebilmek
Aynı kelimeyi tekrar tekrar geçirmenin artık faydadan çok zarar getirdiğini artık duymayan kalmadı. Bunun aslında doğrudan Semantik Arama Ağı ile bir ilgisi var. Örneğin Google, artık bir makalede belirli bir kelimenin geçme sıklığının ne kadardan az ya da fazla olduğunda doğal olmadığını, ne kadarının normal olduğunu kendi öğrenebiliyor. Bu, yapay zekâ destekli olmasından kaynaklı. Çünkü hem belli bir konu için tüm yazıların veritabanına sahip hem de kelimelerin önüne arkasına gelen yeni kelimeler, bağlaçlar ve noktalama işaretleri arası bağlantıları da iyi kurabilmekte. Böylelikle doğal olmayan bir makale yapısı, başlık hiyerarşisi, kelime grubu Google tarafından anlaşılabilmekte. Bir kelimenin eş anlamlı karşılıklarını da bir spam çalışmasına dahil edecek olursanız sonucun değişmeyeceğini söyleyebilirim. Zira yapay zekâ destekli Anlamsal Ağ’da bu veriler zaten sınıflandırılmış ve aynı anlam içerisine dahil edilmiş durumda. Yani siz veya aynı dili kullanan herhangi bir insan farklı iki kelime okurken, arama motorları bu kelimeleri doğrudan aynı gibi değerlendirecektir.4- Farklı içerik formatlarını anlamlandırabilmek
Bilgi türlerini birbirinden ayırabilmek, böylece sonuçları zenginleştirebilmek. Arama motorları, aynı konsepte ait bir fotoğraf ile farklı bir websitesinde yer alan metnin ilişkisini kurabildiğinde kullanıcıların karşısına çok daha iyi sonuçlar çıkarabilmektedir. Aynı durum videolar için de geçerli. Google, ilk arama sonuç sayfasında görseller için ayrı bir alan ayırmaktadır. Bu görsellerin, birlikte sıralama aldığı metin sonuçlarla ilgisinin doğru kurulması gerekmektedir. Ancak bu her zaman kolay değil. Google sizin büyük bir ayı fotoğrafı mı aradığınızı yoksa takımyıldızının fotoğrafını mı aradığınızı bilmek zorunda.Belirli bir konuda imaj, video, sosyal medya profili ve haber sonuçları gibi aynı aramada sonuç alabilecek ancak farklı motivasyonlara hitap eden içerikleri arama motorları iyi sınıflandırabilirse sonuç ekranlarını da daha iyi hale getirebilir. Günümüzde arama motorları bu konuda kendini geliştirdikçe, görseller, videolar, haberler vb sonuçlar için ayrı çerçeveler ayırmaya başlamıştır.
5 – Belirli bir bilgiyi, hiçbir etiketleme olmadan da ayırt edebilmek
Örneğin “Soyadı Tevetoğlu olan şarkıcı Tarkan” ifadesinde “soyadı” kelimesinin anlamını bilen bir arama motoru, bu kelime ile birlikte yazılan diğer kelimelerin “kişinin soyadı” bilgisini verebileceğini bilecektir. Böylece “soyadı” kelimesi artık kendi kendine bir nevi veri işaretleyicisi görevi görecektir ve bu arama motoru ünlülerin soyadlarına dair aramalarda daha doğru yanıtlar verebilecektir.Semantik Arama’nın geleceği: Sesli arama
Semantik Web ve yapay zekâ kullanımına yönelik yatırımların gittikçe artmasının, sürekli artan veri kirliliğinden daha önemli sebepleri de var aslında. Ancak bu bir başka yazının konusu olacağından şimdilik kısa tutacağım. Dünya’da ciddi şekilde artan bir sesli arama kullanım oranı var. Statista verilerine göre insanların %16’sı şimdiden “ilk tercih olarak sesli arama”yı kullanmayı başlamışlar.

https://www.newslabturkey.org/semantik-web-gelecek/
